I wrote the original when the Occupy movement was enjoying its first wave of enthusiasm. There was a popular photo meme of people holding up placards giving some facts about their financial situation and then “I Am the 99%”. And then, of course, came the reaction; photos of people holding up things saying “I’m not the 99%, I worked to get where I am, get a job you hippie” (I’m paraphrasing, but not unfairly I think).
This narrative goes way beyond a few photos on Facebook. It is written deep into our society’s economic philosophy. Choose to work hard and exercise your talents, and you will be rewarded with wealth. Choose to complain and protest instead of knuckling down and getting things done, and you will be rewarded with poverty, for which you will have no-one to blame but yourself.
It would be hard to deny that, other things being equal, you will achieve (and acquire) more if you work than if you don’t. That’s kind of the definition of work, really (if you’re expending effort but not achieving anything, you’re not working, you’re faffing about). But that’s not enough to settle the question. Just because you’ll get more if you work than if you don’t work, doesn’t mean that the difference between someone with money and someone without is that the first person is working and the second one isn’t. It could instead, for instance, be simple luck.
When economists want to test an idea, they use mathematical models. I shall have more to say on economists and their models another time. But I thought the hypothesis that luck cannot make the difference between a rich person and a poor one in a capitalist system was worth testing, and it turned out to be really easy. With a little algebra, you can do it yourself in Microsoft Excel. As I have done, and will now demonstrate.
First, let’s set up our scenario. Angela, Barry, Cathy, Dave, Ellie and Frank work in competing businesses, making the same product. All of them have exactly equal talent and exactly equal work-ethics when it comes to selling their product, so which one actually makes a sale to any given customer is purely random. So we can assign each one, at each sale, a random number. In cell A2, write
=rand()and fill across six columns to cell F2. Then fill down as many trial opportunities as you want; I picked 1024, that being a nice round number if you’re a computer geek. The command rand() in Microsoft Excel generates a random number between 0 and 1.
Columns A to F represent how well each of our six competitors did, as it turned out, towards making the sale. But each customer will only buy one product, so only the best of the six competitors will win in each column. To figure out how many sales each competitor makes in the course of the 1024 trials, you’ll need another set of columns, G to L. Column G represents Angela’s sales, column H Barry’s, column I Cathy’s, and so on. We need to set them to add 1 to that person’s sales total if their random number happens to be the highest. In cell G2, write
=if(a2=max($a2:$f2),g1+1,g1)and fill across to L2, and down for however far you’ve decided to run it. Let me explain that formula. An if() statement in Microsoft Excel has three parts. First you set the condition, which in this case is “If cell A2’s value is the highest of the cells A2 to F2...”. Then a comma, then what happens if the condition is true, which in this case is “Add 1 to the running total”; then another comma, and then what happens if the condition is false, which in this case is “Keep the running total the same as it was”. As you fill the cells across to L2 with the same formula, it does the same test on columns B to F and adds 1, or not, to the appropriate total. Be careful to put the dollar signs in the phrase max($a2:$f2), so that all six new columns still run their test against the first six columns. Fully translated into English, what it does is “If cell A2 has the highest value of A2 to F2, then add 1 to the running total, otherwise leave it as it is.”
What happens? This happens:
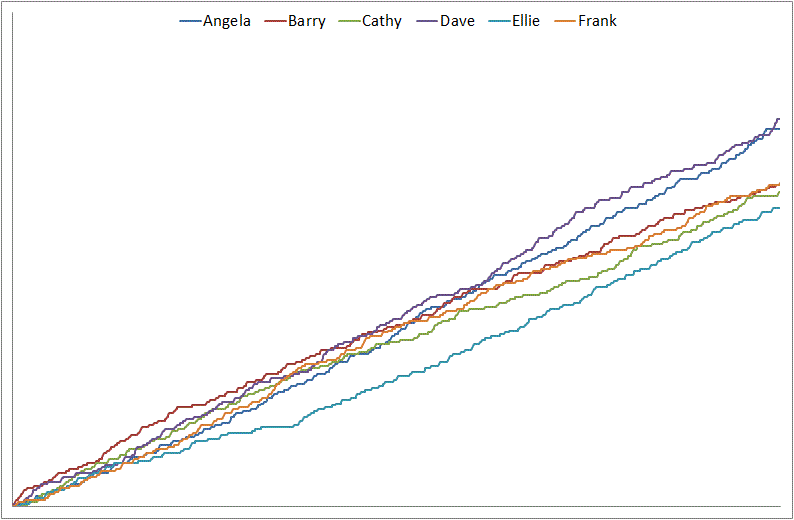
But we’ve forgotten something: this competition takes place in a capitalist environment. That means our six competitors aren’t starting from scratch every time; the profits from each sale become capital for the business – that’s why it’s called capitalism – which can then be directed into advertising, promotions, tidier premises, or whatever, and make it easier to make the next sale. We need a slightly more complex formula to model this. We’ll keep the random numbers and the same test column, but we’ll change the references in that test column so that it now says
=if(m2=max($m2:$r2),g1+1,g1)and now we have to fill in a third formula in columns M to R to make it work. Column M will take the random number representing Alice’s luck that day, and multiply it by the number of sales she’s already made,
=a2*g1except, of course, the first row will be all zeroes because G1 is zero (which will then screw everything up below it). Don’t try changing it to =a2*g2, you’ll get a circular reference error. So why are we multiplying them? Why not add them (=a2+g1)? Well, capital doesn’t automatically add itself to your success; you still have to deploy it appropriately. Your talent, work, and luck – the random number in columns A to F – is a factor modulating the effect of capital, not merely something slapped on the top. Also, remember, the rand() keyword in Excel generates a number between 0 and 1, and if you multiply a whole number by something less than 1, the result is smaller than your original number; so multiplying actually has a more conservative effect on the end result than adding, and I want to see if I can make the point with the most conservative numbers possible.
Here’s a workaround. Type in to cell M2
=a2*(g1+1)and fill across and down as before. Now, I set things up so I’m using the same random numbers each time to make my graphs (I start a new page each time, and fill in columns A to F with sheet1!a2 instead of rand()), and this is the result:

What’s going on? Well, each time Barry makes a sale, he has more capital to compete against the others with, which makes the next sale surer, and the next surer still, and so on. Within quite a short time, the chances of anyone else beating him, no matter how hard they try, dwindle away to practically nothing.
If you’re not comfortable with that arbitrary +1, let’s suppose that it represents help, or money, or whatever, over and beyond the profits from sales. Public services, perhaps. Public transport for goods, free water, stuff like that. But that immediately suggests an additional question. What happens if this outside help gets bigger or smaller? Or, equivalently, what happens if the contribution of capital is proportionately smaller? We needn't model both of these, since they will both do exactly the same to the maths. Let’s set the formula to
=a2*(g1+20)and see what happens:

=a2*(g1+0.05)then we get this:

Next I want to deal with an objection that one or two commenters raised in response to my Note. My models so far have Angela, Barry, Cathy, Dave, Ellie and Frank doubling their businesses’ startup capital with their first sale – hardly a realistic scenario. Perhaps, given more plausible starting conditions, my argument would no longer hold?
Fair enough, I guess. And easily tested. Simply fill in cells G1 to L1 with the value 100, to represent their startup cash, and see what difference that makes. This is what happens now if the competitors don’t avail themselves of the early-luck-magnifying effects of capital:




Now we’re ready for the real test. In the real world, some people are more talented than others, and some people do work harder than others. Perhaps that talent and industry do make a difference, even given the massive skewing effect of capital. For convenience sake, I decided to set our six salespeople’s talent in alphabetical order; Angela would be the best, and Frank the worst, of them. But how to insert it into the formula? Should it be something we multiply the random number by, or something we add to it?
I went with “add”. I figure what an industrious genius achieves on a bad day is still a lot better than what a cognitively limited layabout achieves on a bad day; if talent were a multiplier, then they would both do exactly the same if the randomizer happened to come up with 0. So, first, we string six numbers across the top row:
- 0.5
- 0.3
- 0.1
- -0.1
- -0.3
- -0.5
The formula for columns A to F looks like this:
=rand()+a$1as before replacing rand() with sheet1!a2 if you want to use the same numbers for each test. And what happened?
Without capital, it looked like this:


But there’s another thing we haven’t been bothering to vary, up until now: they’ve all been starting at the same time. What would happen if talented, hard-working Angela were new to the market, and lazy, mediocre Frank were the old guard? Would her talent win out over his early luck? I set up the same model again, but this time I had them enter the competition in reverse order of skill. Frank is there from the start, but I replaced Ellie’s first 128 randomly generated numbers with -2, to make it that she hadn’t come in yet for those first 128 sales; then did the same to Dave’s first 256 numbers, Cathy’s first 384, Barry’s first 512, and Angela’s first 640. (It had to be -2 rather than 0 because Dave, Ellie, and Frank’s random numbers all dip below 0 from time to time.)
This was the result if no-one can accumulate capital (once again, I haven’t bothered to simulate what happens to each of them before they get enough cash to enter the stakes):




Now, if I’ve made a mistake in any of my assumptions or algebra, please feel most free to point it out. I would welcome debate and commentary on this. But by that I mean debate and commentary. If your contribution is going to be along the lines of “I can’t find an error in your methods or premises, but your conclusion has to be wrong because get a job hippie—” don’t bother.
>>All of them have exactly equal talent and exactly equal work-ethics when it comes to selling their product, so which one actually makes a sale to any given customer is purely random.<<
ReplyDeleteYou're initial premise is fundamentally wrong to begin. This is applicable only to the borg who think and do everything in terms of the collective. You do not see people as being distinct and unique with varying degrees of talent and capability to overcome the difficulties they face through innovation and hardwork - that is part and parcel of a capitalistic environment as opposed to a communist borg outlook where everyone is exactly the same with the same talent and same goods. That sounds more like the Stalin's USSR.
And you have to apply a random number using rand() simply shows that this nothing but a pure guessing game.
The premise is not 'fundamentally wrong', it's just that in a world where the market is god, even mathematics must be commie.
DeleteAnonymous #1, I suggest that if reading the start of something makes you so angry you can't keep going, that you don't comment on it and end up looking like a fool. If you had kept reading, you would have found that I made the simulations more complex by gradual steps, including eventually factoring in (large) differences in talent/effort.
DeleteI began with equal participants, however, to show that even had there been no difference at all in talent or effort, pure chance plus the feedback effect of capital would be enough to create large differences in outcome. The point is not that I think that's how things are. The point is that large differences in outcome are not, by themselves, evidence that there are large differences in talent or effort. There might be, or it might be pure luck.
In this version, I factored in startup cash before talent, and when I do get to talent it was always the most talented who won providing (and this is the point) that they all start at the same time. In the earlier article, I did talent first and only introduced startup cash in Part 2. Under those conditions, and with capital, Alice (the most talented) won the race more than half the time, but Barry (the second-most talented) pulled ahead of her in I think it was about a quarter of the runs, and Cathie (the third-most talented) won out in one of fifty trials. In each case, the winner pulled away early, leaving all the others -- including the more talented ones, when there were any -- languishing at the bottom of the graph.
That you need to try to scare me with Stalin and the Borg to bolster your point, is duly noted.
Apologies for writing this as Anonymous as well. I do not have a Google account or one of the other mechanisms.
ReplyDelete2 points on this:
I have to agree that the main premise of a random sale is fundamentally incorrect. Think for yourself how many of your own purchases are random. I can't think of any. The closest I came is when I bought insurance. Other products are bought becaause they are available at a convenient location, I could obtain it where I buy milk, the petrol station is on my way to work, price and quality for vegetables, music in a format I prefer and of an artist I prefer, etc. With larger products and services one usually do more research on the web or wherever.
The differentiating factor between the "contestants" are very definitely not random. It is how well you know people, your product and how people relate to that product.
I intend going through the rest of the calculations a bit closer to understand the explanations of the various scenarios & their outcomes. But this is now merely out of theoretical interest
2. #Daniel- not so clear who really got so angry without thinking what the person said
Of course there is no random number generator in the real world; but people pass in and out of your business and buy things, or not, according to factors that you can neither control nor predict. When you need to simulate something you can neither control nor predict, you use a random number generator. To repeat, the simulations began with six contestants who were exactly evenly matched in competence, including how well they knew people and their product and how people relate to the product. Since they are evenly matched, we have a chance to see whether they could experience large differences in success based solely on the factors which they do not control or predict. And the answer from my simulations is: if they accumulate capital and feed it back into the business, then yes.
DeleteAnonymous #1's answer displayed an ignorance of large parts of the article (s)he was commenting on; I thought stopping reading due to anger was the most charitable cause I could impute for that.